Back in the Noughties, when I first started web programming, data storage choices were straightforward. Your options were limited to RDBMS systems (Oracle if there was a budget, MySQL otherwise); if you to store binary data, then you could use file systems; and, in some cases, where the data was read-only maybe, you’d use a CSV file. Life was simple.
Back then, when I first heard the term ‘NoSQL’, I dismissed it. It’s never good to define something as what it isn’t, and the lack of a structure query language didn’t sound that compelling. But, over the years, NoSQL datastores have become essential, with some of them not being promoted as databases as such. The first one I used extensively was Lucene, which I didn’t really think of as a datastore. (Arguably, it isn’t strictly a datastore, but that’s another discussion).
Now there is a wide range of choices, each with their own specific use cases. I was recently tasked with looking into Couchbase, and the first question to answer is, why use Couchbase at all?
For an overview of Couchbase we can turn to a Linked in blog post on Couchbase’s evolution:
Couchbase is a highly scalable, distributed data store that plays a critical role in LinkedIn’s caching systems. Couchbase was first adopted at LinkedIn in 2012, and it now handles over 10 million queries per second with over 300 clusters in our production, staging, and corporate environments. Couchbase’s replication mechanisms and high performance have enabled us to use Couchbase for a number of mission-critical use cases at LinkedIn.
Wikipedia provides a good summary in their Comparison of Structured Storage software. We can see that Couchbase is a document storage solution, similar to MongoDB, but adding high availability functionality.
Couchbase started as a memcached replacement, adding in features like persistence, replicas, and cluster resizability. Its use as a backend to LinkedIn has demonstrated its potential in large deployments, with LinkedIn having, at one point, “over 2,000 hosts running Couchbase in production with over 300 unique clusters”. Or there were the 100 hosts used for Draw Something – 2 billion drawings were stored, at a rate of up to 3000 per second.
One of the interesting problems with learning a lot of modern technologies is that their potential only really comes out at scale. Speaking as a developer, I would be hard pushed to find a reason to use Couchbase above Mongo unless the use case involved master/client on mobile, or a website I expected to scale massively. But it is easy to get started with a basic Couchbase site thanks to JHipster and docker.
There are clear instructions online for getting going with JHipster, and having a working Couchbase application could be managed within about an hour, even with no JHipster experience. The basic steps are:
- Install JHipster
- Start JHipster and run through the basic application creation options. It’s easiest to work with a monolithic application if you’re new to JHipster. Make sure to pick Couchbase as the database, but otherwise the defaults will work well enough.
- In the newly created application folders, go to the src/main/docker folder, and type the command ‘docker-compose -f couchbase.yml up’
- In the main JHipster folder, use the command ‘./gradlew’ to build and run the Spring Boot application.
- The application can then be viewed at http://localhost:8080. I had to use Chrome to get this working successfully.
The basic JHipster application, with no customisation includes a basic usermanagement system. The couchbase docker instance can be accessed at http://127.0.0.1:8091/, username ‘Adminstrator’, password ‘password’.
Clicking through to the ‘Buckets’ option on the left-handside menu shows the different data partitions available. Clicking on the ‘Documents’ link for the partition we have created shows the basic user data that has been added.
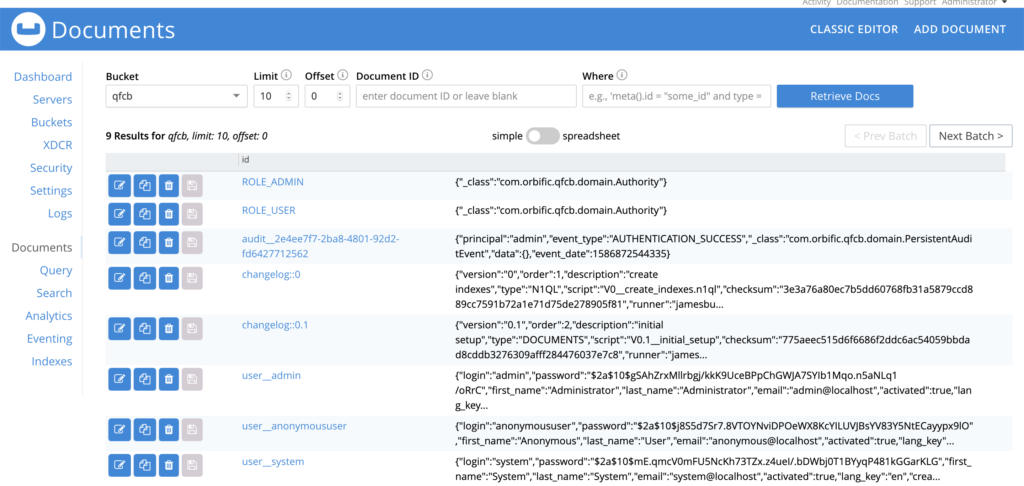
This is not much of an application, but by following the JHipster instructions for creating new entities, we get CRUD options for new pieces of data. While this produces a relatively simple application, JHipster has produced an entire stack, including Spring Data Couchbase. The work so far could be customised to provide a full application, or used as a working example of how to integrate Couchbase into a Spring Boot application. (One advantage of JHipster is that the application produced can be subsequently developed without reference or use of JHipster.)