An interesting effect of writing a series of posts like this is how it clarifies your thinking. I originally planned to introduce a continuous integration server after Javadoc, JUnit and so on. But, as I’ve researched and thought about this, I’ve decided that a continuous integration server is a fundamental tool for development. It should be at the heart of any project.
Good development requires automation. Rather than have any steps carried out manually, we should automate them from the start. I’ve known colleagues who saw Jenkins as the powerhouse of an organisation; that one could have hundreds of jobs, not just passively monitoring repositories to run builds, but to promote code, run reports and even deploy software. Jenkins provides the plugins and the framework for a finely-grained permissions system, based on specific tasks, rather than all the underlying grants and credentials needed.
The problem with CI is that it takes a significant amount of investment and commitment to put in place retrospectively. An organisation that is able to deploy code manually may not feel excited about spending time and energy just to simplify those builds, even when deployments become unwieldy enough to prevent growth. CI also requires discipline – it takes a lot of courage to stop a large organisation until failing unit tests or transitory broken builds are resolved. It’s far easy to carry on with a broken system that seems to work than to push towards an efficient, modern build.
Jenkins runs inside its own application server, separate to the built software. It is available for download from http://jenkins-ci.org/, where there is a Java Web Archive available. The current version is 1.650 and, as discussed in the last section, we need to note this for later use as we scale up.
We need to introduce and document a new environment variable here, JENKINS_HOME, specifying the location where Jenkins stores its internal files. A major issue with Jenkins is that it doesn’t do a good job of separating code from configuration. This poses the question of how to run, maintain and restore Jenkins instances. I will avoid the question of restoration just now – I suspect it will be much simpler after virtualisation is introduced.
The command to run Jenkins is simple; java -jar jenkins.war. The server can then be accessed at its default location, http://localhost:8080/. Running Jenkins on a local machine is not really satisfactory in the long term, but will do for now.
Some initial configuration is required. Again, for the time being, this is system specific and can be found by clicking Manage Jenkins then Configure System. We can point to the current JDK or download a new one. Location of the JDK to be used is another ambiguity that must be dealt with.
I will skip over some of the steps here – there are many good tutorials about Jenkins available, including a very useful O’Reilly book, which I have been using as a reference. The main steps I followed were:
- Install the git plugin (version 2.4.2)
- Install the gradle plugin (version 1.24)
- Install the blue/green balls plugin. By default, Jenkins has its successful builds shown as blue. The Jenkins blog notes that this plugin is in the top ten – and also points out that the red/blue colour scheme is a Japanese thing.
Having set up the basic environment, we add a new freestyle project to build our code. We use gradlew, with both the clean and build targets.
We test the build with running the jar, and that seems to work just fine.
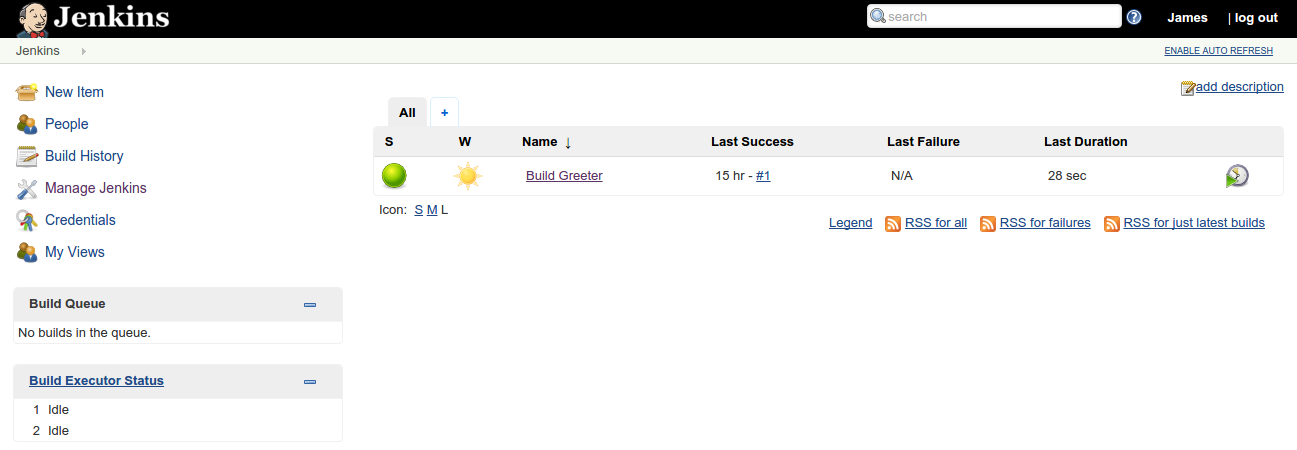
So, there we have it, a slightly clunky local build of Jenkins. I wouldn’t say that this Jenkins set-up is particularly good. However, even with those limitations, it provides a heartbeat for the upcoming stages of the project. If you’d like any more detail on steps that I’ve skipped over, please leave a comment and I’ll edit the text.
The latest commit on github is 392d98e