The ‘hello world’ program is of great importance to developers. It’s usually the first thing written when using a new language or framework, pretty much the simplest thing you can do: output 12 characters (assuming a newline). Writing the hello world program in C, the first time I’d written a compiled program, was an incredible moment for me: I could make the computer do something. This simple idea has an entry on wikipedia and a list of examples.
Hello World is supposed to be simple and there are a few jokes about Java EE hello world programs, mocking the framework for being long-winded and unwieldy – see for example, item 8 in The top Java viral jokes of 2014. In its defence, the contents page shown in the article covers a lot more than code, and is intended to get someone up and running from a bare-bones structure. But Java definitely doesn’t have the concision of Python’s print “Hello, world!”
One of the proud boasts for Spring Boot was how simple it was, with an example application that fitted into a single tweet (the link includes instructions for running it):
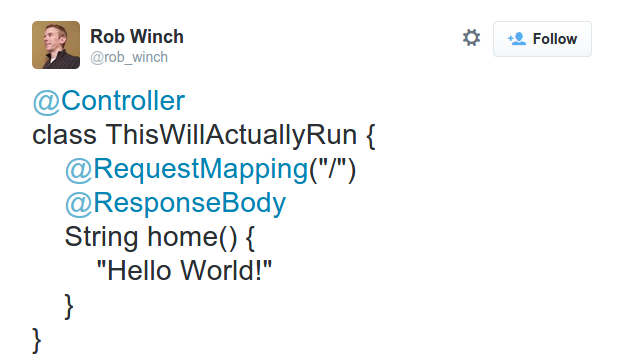
As easy as it is to get a Spring Boot application working, this is only part of the task of the development life-cycle. By focussing on the output, it’s easy to miss a lot of the non-functional aspects of an application. You can deploy a new piece of software to a server without making it easy for developers to work with. This is particularly dangerous with non-technical stakeholders who only see these non-functional requirements indirectly. It’s hard to prioritise infrastructure against features and bug-fixes. They are also incredibly difficult to fit into an application after it goes live.
I’ve recently set up a new application. The initial project was produced using Spring Initializr but, rather than start cutting code, I’ve been thinking about what else I need for a basic application. The essentials include:
- Source control – and, preferably, some sort of branching and versioning strategy
- Continuous integration and related process to make sure that new commits don’t break tests
- A deployment process allowing the same binary to deployed to immutable servers – preferably using some sort of container or virtualisation – preferably with the binary produced once and stored in a centralised location.
- A means of externalising configuration for different environments
- Some sort of monitoring and log management
It’s easy to drop a Spring Boot jar file onto a server and run it, but that’s not going to work in the long term and the easiest time to sort these infrastructural items in place is at a project’s start. The more complicated things become, the harder it is to add them in.
In short: an application isn’t just the software you are writing: it’s also the infrastructure that you put around it. In order to release and maintain an application you need to do a certain amount of work beforehand. Your hello-world application isn’t ready for production until these things are done.