I’ve been meaning to post for some time about my first experiences of programming with ChatGPT, back in January. Ethan Mollick often suggests that people should try doing their job with ChatGPT for at least 10 hours to get a feel for its potential. Playing with ChatGPT for a short time has converted me from an AI cynic to an enthusiast.
Simon Willison wrote about his experiences coding with ChatGPT, concluding that AI-enhanced development makes him more ambitious with his projects.
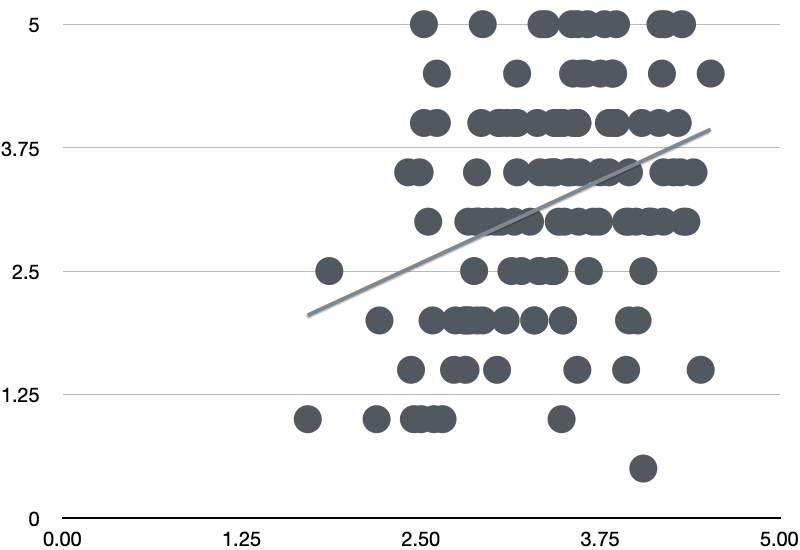
Shortly after I read that post, I had a silly question related to watching movies. I order my watchlist at Letterboxd by the average rating on the site. But I began to wonder whether this was a good way to watch movies. Did my taste actually correlate with the overall site? Or would I be better off finding a different way to order the watch list?
The obvious way to check this is by writing a bit of code to do the analysis, but that seemed like a chore. I decided to put a few prompts into ChatGPT to see whether that helped. Within two minutes, I had a working python programme. There was a little bit of playing around to get the right page element to scrape, but essentially ChatGPT wrote me a piece of code that could load up a CSV file, use data in the CSV file to download a webpage, grab an item from the page and then generate another CSV file with the output.
I started with a simple initial prompt and asked for a series of improvements.
Can you show me an example of how to scrape a webpage using python, please? I need to find the content of an element with an id of “tooltip display-rating”, which is online. I also want to set the user agent to that of a browser.
(I also asked for a random time of between 1 and 2 minutes between each request to the website to be polite. I’m not supposed to scrape Letterboxd but it I figured it was OK as this was for personal use, and I am a paid member.)
This all went pretty well, and ChatGPT also talked me through installing python on my new Mac. The prompts I used were hesitant at first because I didn’t really know how far this was going to go. ChatGPT was also there to talk me through some python specific errors.
When I run this script, I get an error: “ModuleNotFoundError: No module named ‘requests'” What do I need to do to import this module
I get a warning when I run this command: “NotOpenSSLWarning: urllib3 v2 only supports OpenSSL 1.1.1+, currently the ‘ssl’ module is compiled with ‘LibreSSL 2.8.3’.” Is this something I need to fix? What should I do?
Before long I’d got this complete working piece of code and checked my hypothesis. Turns out that’s not a strong enough correlation to say anything either way.
While the example itself is trivial and the output inconclusive, it showed me that it was very possible to write decent quality code very quickly. I rarely use Python, but ChatGPT provided useful assistance in an unfamiliar language. Writing this code from scratch, even in Java, even using Stackoverflow, would have taken more time than it was worth. As Simon Willison says
AI-enhanced development doesn’t just make me more productive: it lowers my bar for when a project is worth investing time in at all. Which means I’m building all sorts of weird and interesting little things that previously I wouldn’t have invested the time in.
My immediate takeaway is that AI tooling has the potential to revolutionise programming. It’s not going to replace programmers, rather it’s going to reduce the threshold for a project to be viable and unlock a lot of work. Tim Harford made the same point recently, looking at the history of the spreadsheet. This is an exciting time, and I’m expecting to be very busy in the next few years. I’m also impressed at how effective a tutor ChatGPT is, breaking down its examples into straightforward steps.
It has taken me far longer to write this post than it did to produce the code.