I’ve now been a software developer for over 20 years. I started out thinking this would be a temporary diversion, but it’s grown to be something I love. I’ve been lucky enough have a wide experience of the industry, from mobile to microservices, and from three-person companies to multi-nationals. So, I decided to compress some of what I’ve learned into some short points:
If a bug isn’t getting fixed this month, then you might as well not track it as you’ll never touch it. (or, to put it more positively – use a zero-bug strategy!)
TDD is never going to take off. Everyone has automated tests, which is great, but I’ve never worked anywhere that used the proper TDD cycle in practise.
Good project management is more important than methodology. Projects are just as messed up under agile as they were under waterfall, but we now have more meetings.
The DRY principle is overrated. Too many people go for this ease of change rather than ease of reading. This is especially problematic in test code, which is mostly write-only.
Focus on the data – I’ve always considered any computer system as a data-store with some code attached, and this works pretty well. If you get the transactions right, everything else will follow.
The best code is simple. If it can’t be followed by junior colleagues, it’s too complicated.
Projects rarely fail for technical reasons. Unless you’re doing something cutting-edge, the failure is due to something within your control. Software development is one of the least important parts of being a developer.
Performance testing is hard.
New technologies get less exciting as you compare them to things you already know. Like, gRPC is just fancy SOAP.
When the pandemic first struck, I put Brighton Java into hibernation. I expected the pandemic to be resolved after maybe six months, and thought I would wait it out. Since that’s not what has happened, it’s time to consider what a local Java User Group should be when we can’t meet together.
The obvious response to the situation is to move events online. Back in March I decided against this. My life already involved a lot of screens, and I couldn’t imagine many other people being excited about watching someone discuss programming on a videoconference call after doing a similar thing all day. For me, the attraction of the events are meeting people in person: it’s sharing of food before the talks, and the conversations afterwards. We’ve had some fantastic talks at Brighton Java, and I’m grateful to all of our speakers, but talks are only part of the reason for running these events.
I do think local user groups are valuable. They provide community at a scale wider than the individual companies in an area. They help companies, by exposing people to ideas and techniques that might not be encountered within a single company. For developers, the group provides a continuity beyond that of a single job.
Over the next few months we’re going to be restarting Brighton Java. Yes, virtual talks will be a part of this. But we’re going to work hard to make these relaxed and enjoyable. We’re going to take advantage of the virtualisation of other groups, and the rich programmes they’ve been running over the past few months. We’re also going to look into novel formats, particularly asynchronous ones.
As ever, we’re interested in hearing from any local developers who are interested in participating or running events. And some announcements from us will be coming soon.
I love this spoof advert, which I first saw back when you had to share your memes by email:
We are social animals, so meetings are an important part of our work. But they can also get in the way of work. I’ve known too many people who claimed to be more effective when they worked from home, or who worked early or late to ‘get things done’. Given how important meetings are, it’s worth spending time getting them right. Running effective meetings is a skill, and too often people don’t bother.
For me the following is essential for any meeting:
A clear summary of the meeting, so people can quickly work out if they need to attend (particularly if they see it on a shared calendar).
A goal – what do we want to get out of this meeting?
An agenda – what specific points are we discussing?
Pre-requisites – what should people read or do to prepare for the session?
Follow-up – after the meeting, a clear summary should be produced and preferably posted to a shared wiki. There should also be a list of action items, with each assigned to a specific individual.
A lot of work is needed around a meeting, but this is worth doing because meetings are expensive. Sometimes I think there should be a clock in the room, showing how much it has cost so far. A one hour meeting for seven people is taking up the equivalent of a person’s work for a day.
In his most recent video for Brigton Java/Silicon Brighton, James Stanier talked about running effective remote meetings:
James provides a great primer on meetings, as well as some useful points that I’d not considered before:
Recurring meetings should have a rolling agenda in a shared document which anyone can add to during the week.
The best meeting is one that does not need to happen, where people can resolve the issues without the need for synchronous time.
James also suggests ‘silent meetings’, allowing time for people to read relevant documents at the start of a meeting.
As well as a chair and a scribe, larger meetings can also use ‘spotters’ to identify people who have not been able to speak or to contribute.
James also suggests recording meetings to reduce the need for them to be synchronous. I don’t like listening to meeting recaps personally, preferring written summaries, but maybe I should try making space for other people’s preferences in meetings that I’m running.
As James says in his presentation, “synchronous time is special”. It’s worth investing some preparation to make sure it is used as well as possible.
Brighton Java has been on hiatus during the pandemic. A lot of groups have gone online, but I was reluctant to do that, since most technical jobs already involve too many video calls these days. There is a lot of excellent material online and, for me, local meet-ups are all about being there in person. I wanted to make sure that any remote event we ran justified people’s time and attention.
Our first event this year, in association with Silicon Brighton, is a series of remote and asynchronous talks by James Stanier. James has been a supporter of Brighton Java for a long time and recently published Become an effective software engineer. On Wednesdays in September he has been providing a series of talks on remote asynchronous working.
So far, the first three talks in the series of five have been posted onto Youtube:
In his first talk, James looked at the current situation, and how the pandemic has forced people into home working. While times are difficult there is a possibility for producing useful long-term change. Remote work is now more prevalent, and some companies are switching to be more flexible than before (Brandwatch, where James is SVP Engineering, has gone remote-first).
James divided the responses to remote work into three groups – those who wanted to be in an office full time, those who wanted to be remote at all times, and those who wanted a sustainable mix of the two. Companies that can be flexible to people’s needs (for example childcare and health) open up a wider pool of talent.
I worked remotely with ribot, mixing my time between home, office, hotels, client sites and airports. Since the pandemic, I’ve been at home only, and I can see a definite advantage to having a base office. But I have also collaborated successfully with entirely remote colleagues, some of whom I never met in person. I believe that flexibility is vital in the modern world.
James himself is fully remote, and his experiences with this led into his second talk, about The Remote Mindset. This is the idea that if one colleague is remote, then companies should behave as if all of them are. James looked at a number of strategies around this. One example here was meetings, and how, if anyone is remote then everyone should interact via screens so there is a level playing field.
The practise of ‘broadcasting’ is also worth encouraging. This is the idea of leaving a public written trace of all smaller group discussions, particular the reasons for any decisions made. This sort of asynchronicity removes the need to be present at specific times. Recording meeting and providing good documentation makes companies more resilient. For example, someone who is ill can catch up easily.
Something else James said, which should be done more is the use of ‘spotters’ in meetings, to draw out people who have not spoken. I also think more companies would benefit by looking at how to make more of the scrum ceremonies asynchronous. I’ve always found the timing of a daily stand-up to be a point of friction.
The third talk looked at Staying Connected through Deliberate Communication. One thing lost through remote working is spontaneous interaction, the serendipity of casual in-person conversations. It’s not just a case of adding a burden of socialising through zoom. (I’ve pretty much stopped all non-work video calls).
James’s suggestions here included setting up informal one-to-one mentoring, and he described how this had been done at Branchwatch. He also made a strong case for connection people (asynchronously) through their passions, whether cooking, pets or exercise. Apparently teams at Brandwatch are competing to cover the distance between the Brighton and Boston offices. James also suggests explicit agenda-free “coffee break” get-togethers as part of the work day.
One of the things I love about these talks is that their form matches with their message. James has allowed the audience to choose topics for future talks, as well as answering specific questions. Some of these have been very useful such as how to handle colleagues who don’t turn on video, or tools for technical white-boarding.
The fourth talk will be live on Wednesday afternoon, on the topic of managing remote meetings. If you would like a reminder about it, please check the Meetup Page.
Back in the Noughties, when I first started web programming, data storage choices were straightforward. Your options were limited to RDBMS systems (Oracle if there was a budget, MySQL otherwise); if you to store binary data, then you could use file systems; and, in some cases, where the data was read-only maybe, you’d use a CSV file. Life was simple.
Back then, when I first heard the term ‘NoSQL’, I dismissed it. It’s never good to define something as what it isn’t, and the lack of a structure query language didn’t sound that compelling. But, over the years, NoSQL datastores have become essential, with some of them not being promoted as databases as such. The first one I used extensively was Lucene, which I didn’t really think of as a datastore. (Arguably, it isn’t strictly a datastore, but that’s another discussion).
Now there is a wide range of choices, each with their own specific use cases. I was recently tasked with looking into Couchbase, and the first question to answer is, why use Couchbase at all?
For an overview of Couchbase we can turn to a Linked in blog post on Couchbase’s evolution:
Couchbase is a highly scalable, distributed data store that plays a critical role in LinkedIn’s caching systems. Couchbase was first adopted at LinkedIn in 2012, and it now handles over 10 million queries per second with over 300 clusters in our production, staging, and corporate environments. Couchbase’s replication mechanisms and high performance have enabled us to use Couchbase for a number of mission-critical use cases at LinkedIn.
Wikipedia provides a good summary in their Comparison of Structured Storage software. We can see that Couchbase is a document storage solution, similar to MongoDB, but adding high availability functionality.
Couchbase started as a memcached replacement, adding in features like persistence, replicas, and cluster resizability. Its use as a backend to LinkedIn has demonstrated its potential in large deployments, with LinkedIn having, at one point, “over 2,000 hosts running Couchbase in production with over 300 unique clusters”. Or there were the 100 hosts used for Draw Something – 2 billion drawings were stored, at a rate of up to 3000 per second.
One of the interesting problems with learning a lot of modern technologies is that their potential only really comes out at scale. Speaking as a developer, I would be hard pushed to find a reason to use Couchbase above Mongo unless the use case involved master/client on mobile, or a website I expected to scale massively. But it is easy to get started with a basic Couchbase site thanks to JHipster and docker.
There are clear instructions online for getting going with JHipster, and having a working Couchbase application could be managed within about an hour, even with no JHipster experience. The basic steps are:
Start JHipster and run through the basic application creation options. It’s easiest to work with a monolithic application if you’re new to JHipster. Make sure to pick Couchbase as the database, but otherwise the defaults will work well enough.
In the newly created application folders, go to the src/main/docker folder, and type the command ‘docker-compose -f couchbase.yml up’
In the main JHipster folder, use the command ‘./gradlew’ to build and run the Spring Boot application.
The application can then be viewed at http://localhost:8080. I had to use Chrome to get this working successfully.
The basic JHipster application, with no customisation includes a basic usermanagement system. The couchbase docker instance can be accessed at http://127.0.0.1:8091/, username ‘Adminstrator’, password ‘password’.
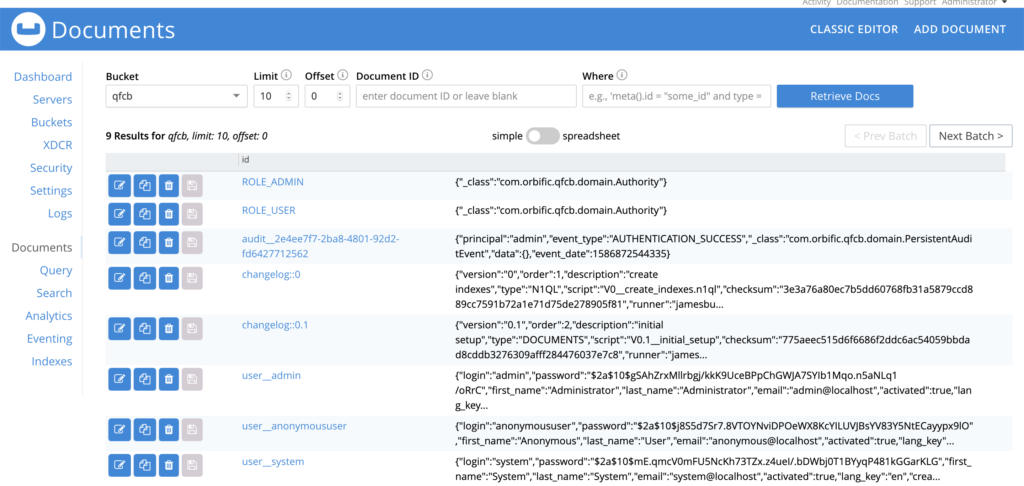
Clicking through to the ‘Buckets’ option on the left-handside menu shows the different data partitions available. Clicking on the ‘Documents’ link for the partition we have created shows the basic user data that has been added.
This is not much of an application, but by following the JHipster instructions for creating new entities, we get CRUD options for new pieces of data. While this produces a relatively simple application, JHipster has produced an entire stack, including Spring Data Couchbase. The work so far could be customised to provide a full application, or used as a working example of how to integrate Couchbase into a Spring Boot application. (One advantage of JHipster is that the application produced can be subsequently developed without reference or use of JHipster.)
It’s a good talk, but I think the title is a little restrictive. Many of the problems with microservices are problems with all computer systems – it’s just that microservices punish mistakes more brutally.
In a recent job interview I was asked if I could deal with the specific demands of microservices when (the interviewer felt) much of my experience involved monoliths or small groups of services. My response was that principles such as loose coupling, monitoring, and resilience are needed in all systems .
It’s a rare system that has no external dependencies. I once worked with a monolithic system that made a call to Salesforce as part of the login process. When Saleforce went down, users could not log into the system. The issue was obvious – we had to manage failures in the external dependency. Microservices, by involving many more dependencies, force people to engage with this; or else, suffer massive disruption and downtime.
One of the most interesting things about Cockroft’s talk was his observation about the problem with disaster recovery:
Your switching processes, and code, and practices are not well-tested. You’ve got an unreliable switch between your primary and backup datacenter. You might as well just not have the backup datacenter.
The answer here is to make the failure systems part of the normal workings; to be constantly switching between datacenters, for example.
There was also an interested related point about the chaos monkey. This was not just about testing resilience:
We were enforcing autoscaling. We wanted to be able to scale down. If you think of an autoscaler scaling up and scaling down, to scale down, it has to be able to kill instances. The Chaos Monkey was there to enforce the ability to scale down horizontally scaled workloads. That was actually what it was for. It was to make sure you didn’t put stateful machine, stateful workloads in autoscalers. Then you can have this badge of honor gamified a bit. “My app survived all of this chaos testing, and it’s running in this super high availability environment, and your app didn’t. Do you mean your app’s not important?” You can gamify it a bit.
Many of the principles discussed in relation to massive companies such as Netflix are needed by everyone. The good thing about this is that the tools being produced empower companies of all sizes. Microservices enforce a more mature attitude to failure; but failures occur in systems of all sizes.
We’ve just announced the first two events for Brighton Java in 2020. On Tuesday January 28th, we have a talk on Serialization Vulnerabilities in Java from Joe Beeton and sponsored by Amex.
The talk looks at how Java applications can be vulnerable to serialization attacks, and how they can be protected. The talk will be useful to Java developers of all experience levels. Joe has done some interesting work around this topic, which I’m looking forward to hearing more about.
In February, we have Luke Whiting talking on Kubernetes in the Data Center: Theory vs Reality. This talk will be a little different to the usual format. Luke will start with a talk he gave at the start of a project, following it up with the lessons learned in hindsight.
We’re also putting together future events, including a collaboration with Silicon Brighton and an exciting speaker for April. But we’re always on the lookout for new speakers, and welcome people of all levels – introductory talks on a topic are just as useful as expert sessions. If you’ve not spoken before, we’re happy to help you prepare. Either leave a comment, or email james@orbific.com
I’m also hoping to do some practical first steps sessions. The JVM eco-system feels more exciting than ever right now; but it’s sometimes hard to work out how to begin with new topics. Hopefully, we can provide a collaborative environment for this. More soon.
How many open tickets do you have in your tracking software? And how many tickets were closed in the last six months?
In a lot of places I’ve worked, the relative size of these two numbers meant it would take years to clear all the open tickets. When the company has been going a long time, there are even sometimes tickets relating to issues that were fixed years before, often as the side-effect of another change.
These other tickets turn up in searches and need to be considered, if only in a small way, when new work is prioritised. While it’s useful to have long-term plans and roadmaps, I am not convinced that the ticketing system is the right place.
The more tickets you have, the more temptation there is to throw things in the backlog that need doing one day. Things get lost, and it’s hard to be certain you’re working on the most important thing. If something is not going to get done in the next year, there’s no point tracking it.
What about bugs and live issues? The best platforms I’ve worked on have had a zero-defect policy. If something is worth fixing, it should be fixed as soon as possible. If you’re prepared to live with it, and you’re not going to get round to fixing it any time soon… why bother recording it?
What about technical debt? If your technical debt is causing problems, you’ll be able to figure the most important thing to focus on. The rest of those things that you might get onto next year… Still might not be a bug enough problem to actually solve next year.
Massive backlogs are a weight we don’t need to carry. Tickets you’d love to do but won’t are clutter. They’re self-delusion.
Do some new year tidying up: delete the tickets you’re not going to work on, and focus on what you actually can do.
Last week, I visited J-O-X, the Oxford Java user group, to give a talk on JHipster and to meet the organisers.
I’ve been running the Brighton Java group since 2012, when I founded it with David Pashley. The group has ebbed and flowed over the years and, together with the current organising team, we’re always looking at ways to improve the group. Visiting different user groups is a part of this. It’s a chance to see what has worked for them, and improvements we can make.
The other good thing about visiting Oxford was finally being able to visit the Pitt-Rivers museum, which was as strange and as wonderful as I’d been told. I saw lots of amazing things, including this figure. I wrote a story based on a photo of this, which was later printed as a postcard promoting the Quick Fictions app:
I don’t think I gave the best delivery of my JHipster talk, being slightly spooked by technical issues that made me decide against the live demo. But people seemed to enjoy it, and I had some interesting questions, as well as some interesting discussions afterwards. I discovered that many of the people attending worked for the company Diffblue and had PhDs – it could have been a slightly intimidating crowd, but everyone was very friendly.
The other speaker was Pascal Kesseli, who spoke about DiffBlue’s JBMC tool (also on github). It’s a Bounded Model Checker that attempts to find bugs in software. Based on the demo, this looks like a fascinating technology, with the potential to find bugs in software that are not obvious, even after unit testing.
Thank you to Haybrook IT Resourcing Limited for organising the event, and to DiffBlue for their sponsorship.
At the start of last week, I ran an API Workshop for Brighton Java. It was a fun event, and people enjoyed it. But nothing is ever perfect, and I wanted to note some potential improvements.
The workshop had been designed as being freeform. As outlined in the previous post, I wanted to provide people a space where they could play with ideas. Everyone made some progress towards an idea, but future sessions could be much more engaging. The main changes to make are:
There need to be a series of wins at different levels. The first stage would be getting the basic example working, then perhaps amending that, and then converting the code for new functionality. Obviously, not all attendees will manage all of this, but everyone should come out of the workshop having achieved something.
While I had provided a working example and asked people to bring along a laptop and IDE, not everyone found it straightforward to get this example working . Java is never going to achiece the ‘write once, run everywhere‘ nirvana that Sun promised. Some people didn’t have a compatible JDK on their machine; others were more comfortable with Android and wanted to convert the example. One possibility is using VMs as a fallback, but that brings its own issues.
A workshop that was already potentially complicated had the additional challenge of picking an idea to work on. I should have prepared a set of possible examples, which people be inspired by, or even reproduce.
Running an effective workshop in a couple of hours is challenging, which is why good faciliators are in-demand and highly paid (and why it takes years of training to become a teacher). But I’m very excited about what I could achieve with some more preparation on the points above. It’s definitely a session I’d like to run again.