Flyway
After my recent experiment I’m going to add in databases. One of the pain points in most deployments I’ve worked with is the need for database updates. These were always manually applied and, in some cases, required a time-consuming reversion if things went wrong. And, of course, the production database would never be quite in the state expected.
There are options for automatic deployment including Flyway and Liquibase. These maintain a database version number and apply any new scripts at application start-up. This also makes it easier to test deployments, as it becomes more obvious what state a particular database should be in. I’ve never understood why Flyway isn’t more commonly used. I think the main objection was that it requires a little more care in writing database scripts, taking care to make sure scripts are backwardly-compatible.
The advantage of a small test project is being able to test adding things without worrying about complicated regression problems. Adding flyway on its own also means that I can then add Spring Data on top of this and the database structure will always be under version control. Flyway has been chosen here since it uses standard SQL scripts rather than the custom language used by liquibase.
With Spring Boot, only two files needed to be edited to provide flyway support. The first was some additional dependencies to the build.gradle file:
compile "org.flywaydb:flyway-core:4.0"
compile("org.springframework.boot:spring-boot-starter-data-jpa")
compile 'mysql:mysql-connector-java:5.1.38'
I also added a new src/main/resources/application.properties file which contained the database parameters. These are taken from environmental variables, meaning that the database credentials are not stored in the git repository anywhere. It also means the same war file can used on any server.
spring.datasource.url=${DB_URL}
spring.datasource.username=${DB_USERNAME}
spring.datasource.password=${DB_PASSWORD}
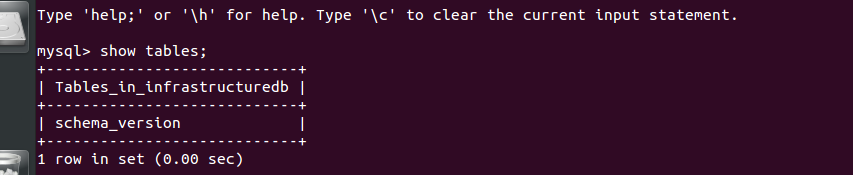
These changes in their own are enough to get flyway working. The Spring Boot logs show some relevant output, and at the end a new table is added to the database:
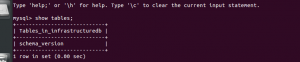
Adding database output to the application
The good thing about adding Flyway to the application before we have any database entries is that the database can be completely maintained through versioning. The next step is to add some more interesting database objects than a schema_version table.
I’m going to make a basic page displaying some page titles. On another occasion I can then connect this to Spring Integration to make a simple RSS reader. I’m going to summarise the changes that were made rather than go into them in detail as there are good Spring Guides on accessing data through JPA.
Gradle
A new dependency was needed in the gradle script to set up thymeleaf
compile("org.springframework.boot:spring-boot-starter-thymeleaf")
There was also a missing dependency needed to set up Tomcat. While there was a war file being produced beforehand, it was not doing some of the more advanced setup:
providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat'
Database Script
There is a simple database script in src/main/resources/db/migration which creates an entries table and adds a couple of entries.
Thymeleaf templates
There is a new index template in src/main/resources/templates, where the body iterates through the entries in the feeds table:
<body>
<p th:text="'Hello, ' + ${name} + '!'" />
<p th:each="entry : ${entries}"
th:text="${entry.title}">"${entry.link}"</p>
</body>
</html>
Entry.java
We add a new database entry object, which links to the entries table and contains two properties, title and link.
EntryRepository.java
A standard Spring Data repository containing a findAll() method.
Greeter.java
This class required a number of changes to use the repository class as well as to enable it to work with Tomcat. Spring MVC was used to provide values for the templates:
model.addAttribute("entries", entryRepository.findAll());
The main catch was changing the class to provide a new definition:
@Controller
@SpringBootApplication
public class Greeter extends SpringBootServletInitializer implements WebApplicationInitializer {
There was also a new method needed to supply the basic configuration.
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder application) {
return application.sources(Greeter.class);
}
Deploying to RDS
Setting up the RDS instance in AWS was relatively easy. The free tier I’m currently using provides a free small database, and there’s even a checkbox during set-up to restrict the available choices to ones under the free option. The contextual help here is excellent. With little work it was possible to set up a user on the instance and access them remotely.
There was an option in the AWS set-up to add the environmental variables for the Elastic Beanstalk instance. This supplied the database credentials to the war file.
Deploying the war to AWS via Jenkins required no changes, as it was already set-up. The only problem I had centered around making the database instance accessible to security groups – which would have been solved if I’d RTFM’d.
Conclusion
The main takeaway from this is that continous deployment is not, in itself, a complicated thing. It’s not taken long to set up a proof of concept, with a database backed site updating through Flyway. This basic model would be easy to replicate.
I’m going to make a few more additions to this example, adding Spring Integration to read from an RSS database, and some tidying up on the front end, most likely with Angular and Bootstrap. This will then provide the basis for building quick Java application prototypes.
And, of course, the information from these posts will be tidied up and incorporated back into my Java infrastructure posts.